Experiments! AB tests! On one hand it seems like everybody's doing it and on the other hand I regularly get the impression that a lot of people have found it to be more cumbersome than it’s worth. Worse, some blog posts I see imply that it’s leading folks down a path of micro-optimizations based on totally insignificant amounts of data. So what does it look like to have an AB testing framework that actually works?
At ezCater we’ve spent a good bit of time getting our experiment infrastructure in place and we'd like to share what we’ve come up with because we quite like where we’ve ended up. I've split these posts up into 4 sections:
- Architecture, Event Taxonomy & Warehousing (you are here)
- Tracking Experiments: The Exposure Event
- Deciding When to Call an Experiment: p-value Graphs
- Implementing p-value Graphs in SQL
System Architecture
Let's start with a high level picture of what I've found to be the ideal event tracking architecture and then I can highlight a few of the important points. In my opinion you should shoot for this, though simpler versions are totally acceptable.
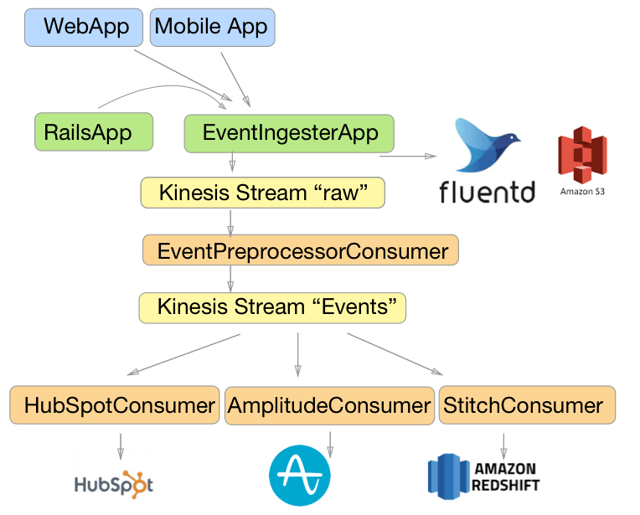
Key features of Architecture
A single chokepoint
Always send events through a single choke point. It's damn tempting to just have the mobile app use the Amplitude SDK directly, but you don't want to explain why your data analyst can see some events but not others. Events are events are events.
Save raw data immediately
You're going to want to mess with your data. You're going to massage it. You're going to hydrate it with ancillary data sources. You're going to let a bug sneak in and if that bug breaks your ingestion before it's in your durable queue you're going to be very sad. Before you do anything, output the raw event tracking data to S3.
Use a multi-consumer queue
Kafka / Kinesis etc are both fine. The important thing is that you're going to have 4-5 consumers sending data to your various tracking tools. If one of your tracking tools barfs you want to be able to retry it and only it. Not retry the whole "track event" job.
Consider 2 queues
It can be pretty awesome to "hydrate" or "decorate" your events as they go through the system. Don't make the mistake of doing this in each consumer. Queues are cheap, have lots.
Figure out how you're going to transform event json to columns
I'm going to strongly recommend that you get your data in Redshift in addition to whatever else you're using. Critical to that is figuring out what you're going to do when clients pass you new properties. We use StitchData to automatically create columns for us. If you were happy with a zero tolerance approach to new columns you can probably suffice with KinesisFirehose.
Stamp Events with a GUID
Since you've got a single chokepoint, you've got a great opportunity to help yourself out in the future by uniquely tagging all the events. Can you tell I forgot to do this? Yeah :/
All events should be queryable from Redshift.
I don’t care if you use Amplitude, MixPanel, Heap, Localytics, or some fabulous homegrown UI. There are going to be weird puzzles with your data and the only reasonable way to debug what is going on is to have full SQL access to your data.
Event Taxonomy
Event taxonomy. Sounds boring right?! Not at all. First you'll need a squirrel, a scalpel and a large bag of cotton. Ah no sorry, that's taxidermy. Sorry.
Taxonomy! In the next few parts of this blog series we’re going to get into the details of actually tracking and evaluating experiments, but I can’t emphasize enough how important it is to not skip the basics. Trust me when I say that I’m somebody that ALWAYS skips the basics, but the fact is that you are going to live with the results of your event taxonomy for a long long time and you’ve got a choice between:
- Getting it right, or
- Doing horrible SQL contortions & constantly having to re-explain what all of your events mean for the rest of your life
Let’s see what option 1 looks like, shall we?
What does a taxonomy need to acheive?
If you take away nothing else from this post take away this: the way we track our events should be driven by how we want to query them. With that in mind, let's look at the taxonomy from the outside in. Here are the basic things I expect our taxonomy to enable.
All events should be easy to find via autocomplete.
Seems like a small enough one to be not worth mentioning, but you will thank me, I promise. Autocomplete is the interface to your event hierarchy. Easy to find via autocomplete means hierarchy and discoverability. I guarantee people will build funnels with the “wrong” events if you don’t do this.
All events should have a human optimized name.
A new Product Manager should be able to build reliable funnels from the correct events without asking anybody "what does X really mean?"
We should be able to aggregate without regular expressions and "like" SQL.
This is the big one. We're probably going to have 50-500 different events. If we simply give them names, we're going to quickly end up regex-ing and substring-ing and like-ing in order to perform reasonable aggregations like "how many people use anything in the store", "how many people edit something in their profile". The sql you want is going to be:
where category = 'profile'
not
where event_name in ('profile-pic-update', 'profile-name-update', 'changed-email-address', 'updated-passwords')
again, make it easy on yourself.
All events should be documented before they're sent
Yes, I know you're going to cheat, but you should at least aim for this. Analysis is going to take 10-100x more effort than just instrumenting the code. Anything that makes understanding WTF is happening better is worth it.
So let's see what this looks like in practice.
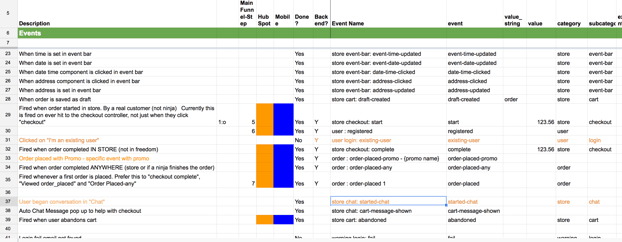
Here's an example of the Google sheet of our event taxonomy. Note the columns:
Description: Human readable. This is where you put the subtle distinctions between something like “checkout-complete” and “order-placed”.
EventName: This is a compound name. Why? Because it enforces good hierarchy and naming. Something like =CONCATENATE(L25, " ", M25,": ", I25, " ", R25) or "Billing errors: charge-failed"
Category: required - Big picture what is this? Store? Admin? Billing?
SubCategory: Highly recommended
Event: required
ValueInt / ValueString: Since everything is getting stored in Redshift (which has a schema) we need to be a bit judicious with our columns. I like having a few “typed freebie” columns so that not every event which wants to store some associated info has to add new columns to my database. Definitely a judgement call for when it’s more clear to have things get a column of their own.
So what does that look like as an actual RedShift schema?
Redshift Schema Details
Text255 is pretty good encoding for most of these columns. You ought not have too too many distinct values in them
Interleaved sort keys are amazing. https://blog.chartio.com/blog/understanding-interleaved-sort-keys-in-amazon-redshift-part-1 is an amazing blog post that explains them. Do be careful though because unless you regularly VACUUM REINDEX it's likely that you're not actually getting any value out of them.
UTM columns. I'm a huge fan of leveraging the utm params on events in order to help with all manner of attribution. Attribution is a whole series of blog posts into and of itself, but I'll just leave these here. :)
event_guid This is a guid that we stamp on each event the very second we see it. Extraordinarily useful if you end up in a situation where Redshift or some other system has barfed and you're trying to reconcile which events are in which systems.
experiment_test and experiment_result. We'll cover those in part II.
Enforcing Hierarchy in Code
So this schema is all well and good, but somehow you've still got to ensure that developers are following it. To implement this I suppose it depends on your language and how much you’ve bought into my rigorous up front focus on event naming, but what we’ve found works is setting up constants for each of the events in code and then referencing those when we want to track an event (as opposed to freeform track(String eventName) all over the place).
Wrap Up
Hopefully this will give you a bit of a hook into what your event taxonomy should look like. If you're starting a new project you're in luck because it really shouldn't take a ton of time to get your Google sheet in order before you begin. If you've got an existing project I'd sure consider breaking some eggs to get to a better place. You'll thank yourself later.
Like where this is headed? Try Part 2 Tracking the exposure event
