It begins: The promotion
 You’re a SaaS business. You've been acquiring customers and on average they're worth about X. Somebody clever suggests a promotion, "$5off your first order".
You’re a SaaS business. You've been acquiring customers and on average they're worth about X. Somebody clever suggests a promotion, "$5off your first order".
You release it and boom! Conversion rates increase, the number of new customers increase. Yay, right?
But then someone asks that pernicious question "are we sure these are still 'good' customers"?
Put simply "Is the promotion worth it?”
Estimating Lifetime Value: A summary of my Googling
If you're like me, you'll start googling around to see how one estimates customer lifetime value, but unfortunately I don't expect you'll get too far. Most discussions of LTV revolve around:
- Average order size
- Average customer lifetime
- Average orders per year
- Multiplication
- Optional shenanigans around weighted cost of capital
Maybe this is fine at a high level, but it completely falls apart once we consider that new customers might not behave like old customers. If you've been acquiring customers with $500 in lifetime revenue and then suddenly start giving people $200 off to sign up it stands to reason that you may be attracting totally different people. If we just assume they are worth $500 we will likely be very disappointed. To ignore this is dangerous in the extreme.
So what are we to do? Option one is to measure how much value our cohorts actually create in a year and track that. Deploy a promotion. Wait a year. See whether ARPU went down. Easy! But this will give us 1 year experiment cycles and that is obviously not going to work.
It all boils down to the question of “given X days of customer data, how can I predict their year one revenue and at what accuracy”.
At ezCater we call this predicting EY1R. (Estimated Year 1 Revenue).
Aside: Why Y1R instead of LTV/CLV?
We standardized on Y1R instead of LTV because there is a strong correlation for us (probably you too). But it's much much easier to talk about a number that we can reason about without having to discuss Weighted Cost of Capital & long term retention curves all the time.
For example: if your retention is 99% and people spend $100/yr then your “CLV” is… well, when do you stop? 10 years out 99% retention expects you to have 91% of your users. 20 years? 100? Ok, so weighted cost of capital reduces future revenue… but, honestly, once you say weighted cost of capital eyes glaze over and now you have a metric that’s fun to argue about but no one really understands. Y1R is clear. Y2R is clear. Pick the timeframe you want, but I strongly suggest banishing the terms LTV & CLV.
What is to be done?
So “given X days of customer data, how can I predict their year one revenue?” How do we go about actually solving this? Well, step one is to pull out our data and see what it looks like.
1. Getting the data
Page views. AdWords information. HubSpot attributes. Order data. Usage events. If we want to predict how valuable a user will be in their first year on only N days of data we’re going to need to collect every piece of information we have.
At ezCater this is accomplished with 2 tools. Amazon’s Redshift and StitchData. You can read a little bit more about our architecture in AB Testing at ezCater Part 1: Event Taxonomy & Warehousing
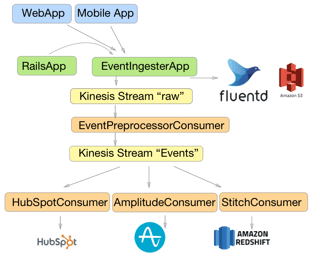
What’s not covered in that piece is how we use Stitch, not just to get our events into the warehouse, but also to pull in a host of data from other services we use. You can see their integration list to see what is available. The particular reason we chose Stitch for this is that the code they run to actually suck in data is open source. We’re on the cutting edge in a few places and it’s been invaluable to be able to just pull request what we need.
With all of the data in our warehouse, it’s time to pull together a single view of our users.
2. Developing a training set
To start, we pull out every possible feature we can think of that is calculable during a users first X days. For example:
- Marketing source, campaign, keyword, etc
- Which caterer they landed on
- What type of food that caterer serves
- What day of week the order was for
- How many orders they made in their first few days
- The metro region of the caterer
Next to that you need the “ActualY1R” for people that have > 1 Year of data.
After that it’s simply a question of
- Partitioning a training set
- Choosing a machine learning algorithm
- Understanding whether you’re overfitting
- Learning about test sets
- Tweaking L2 and L1 regularization
- Fiddling with learning rate
- Tweaking bin sizes and numbers of decision trees
- Wondering whether you should try a neural net
- And sorting through 19000 CSVs full of numbers
I'll wait here while you finish reading The Elements of Statistical Learning.
And then...
Ok, easy! But then finance asks you whether they can build all their models off your prediction and “how accurate are they?"
Feeling clever you say “R^2 is 0.63”.
To which your CFO replies “Neat. How accurate are they?”
So you try again and say “RSME is $130”
To which he replies, “so you mean that, on average, our users are worth $100 and you can predict with an error of +- $130?”
And you say… "um...."
So how well did it work?
Read on for “Part 2: What did we learn about machine learning”
Note: All the numbers in this have been fuzzed a bit (ok fine a lot) so as to not share ALL the details of our business in one blog post :)
