What is a Multi-armed Bandit Experiment?
Problem Intuition
Let’s imagine you’ve decided to hit up the casino and try your luck at the slots. You don’t know which slots are best, but you have reason to believe that some of the slot machines are better than others. You only have a limited amount of money to play with, so you want to play each of the machines enough to learn which is going to be best (explore), and then as you learn, play the best machines most frequently to maximize your return (exploit). Choosing which machine to play is referred to as the exploration / exploitation dilemma.
Difference between Multi Armed Bandits and AB Tests
Under a standard AB test framework, the test would run for a predetermined amount of time or until it has determined a winner, usually by statistical significance. The goal of an AB test is to maximize exploration, and control the test so that any changes in conversion rate are exclusively attributable to the variant. In the slot machine example above, an AB test would involve picking two machines, playing them in an alternating fashion, and then determining how much money you made from each.
However, the downside is that an AB test is slow to exploit--you may quickly learn that one variant performs much worse, but for the sake of continuity and rigor, you must continue to give it the same amount of traffic. Conversely, a multi armed bandit will immediately send more traffic to the variant that is performing best. See below for an example of how a multi armed bandit test distribution changes over time.

When should I use a Multi Armed Bandit vs an AB Test?
Should we exclusively use multi-armed bandit tests? Not quite. If we think back to the hypothetical trip to the casino above, we can see some built in assumptions about the shape of a problem--namely, the analysis / simplicity of the conversion process. It’s very clear whether or not a single pull of a slot machine arm yields money, and likewise, it’s very straightforward to look at raw conversion rate based on which text you use in the page’s H1 tag.
However, if you’re looking to experiment with the entire layout of the page, or adding new site features, the analysis becomes much more complex. Maybe the conversion rate goes up, but so does the bounce rate. Or maybe the EY1R (i.e. estimated LTV) goes down, or fulfillment issues go up. The complexity introduces a possibility that the variant with the higher conversion rate actually loses, and we don’t want to use that variant going forward. In this case, a responsive experiment makes much less sense than a well controlled AB test that allows for a full analysis in post.
Examples of good multi armed bandit tests:
-
Copy changes
-
Images
-
Small display changes (different font family / sizes, different padding amounts, etc.)
Examples where AB test should be used:
-
Adding / removing a step in the order flow
-
Changing the layout of a landing page
-
Changing the search algorithm
How We Built It
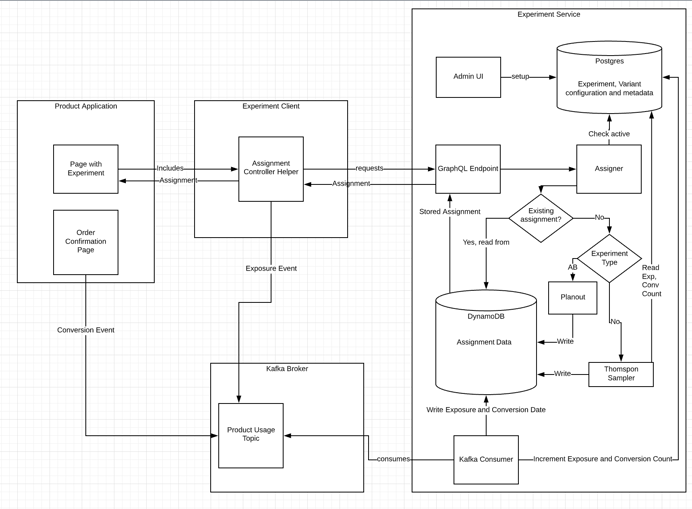
Assignment API
Once the product manager sets up the experiment and variants in an admin UI, the engineering team can include our experiments client in their application. We used Facebook's Planout for our AB test assignments, and Thompson Sampling for our multi-armed bandit assignments (more on that later!). The back end uses DynamoDB to store assignments to make sure we're showing the user the same experience each time they come back to the page. From a performance perspective, DynamoDB supports much faster writes and reads than Postgres, and our access pattern is straightforward, making it the best tool for this job.
Feeding data back to the experiment
At its core, the multi-armed bandit only needs to know about exposures and conversions. Because these events happen in other applications, we need a way to signal to the experiments service when they occur without negatively impacting page load times. We can leverage a Kafka event stream here, as our SRE team has built a Kubernetes platform that makes deploying Kafka consumers very straightforward. Our client standardizes the exposure event, and the admin UI allows you to define the conversion event names to look for in the setup process. Our ecommerce flow emits several different conversion events that can be optimized for. We run a Kafka consumer on the event stream to look for exposures and conversions, using DynamoDB to write exposure and conversion dates on the assignment to ensure that we don’t count any events twice.
Adjusting the New Assignment Distribution
The key feature of a multi-armed bandit experiment is its ability to react to data and adjust the new assignment distribution. All multi armed bandit tests start by distributing the traffic equally among the variants. Now that we have the exposure and conversion data, how should we adjust the distribution? There are a a few different solutions to the multi armed bandit problem, we can discuss benefits and drawbacks of each.
Naive Algorithm
A naive algorithm is not much different than an AB test, in that it will supply each variant with N page views, and will then choose a winner based on the observed conversion rate. The obvious drawbacks here include a lack of awareness of conversion lag, no exploitation while the variants have <N views, and no possibility of recovering if choosing the losing variant after N page views. We won’t discuss this one further, but any solution we choose should easily beat this one.
Epsilon Greedy
In this framework, we pick a number between 0 and 1, Epsilon (ε). When a request for a new assignment comes in, we pick the current leader in observed conversion rate (1 - ε)% of the time, and then sample uniformly from the remaining variants the remainder of the time. The benefit is that we’re always supplying each variant with traffic, and if one variant does particularly well at the beginning, it will be forced to “prove it” by receiving more traffic.
The downside is that ε does not change as the test goes on, so a test with 100 total views gets treated the same as a test with 10,000 total views, even though we are much more confident of the conclusion in the latter case. It’s also very difficult to properly set ε. If you set it too low, it may take a long time to fully explore each variant, but if you set it too high, it won’t properly exploit once it’s clear which is the winner.
Thompson Sampling
Time to break out the Bayesian Statistics books! In probability theory, there are two general approaches, frequentist and Bayesian. Frequentist relies solely on the observed data, whereas Bayesian relies on a prior distribution, and shifts that distribution based on observed data to arrive at a posterior distribution. The key difference is how these disciplines proceed when there is limited data. Consider the following example: if you play a basketball game, and make 5/5 free throws, a frequentist would say that you have a 100% probability of making your next free throw. Meanwhile, in Bayesian statistics, they may recognize that the average basketball player only makes 70% of their free throws, and while you’ve made a few free throws, that’s only enough data to drag your expected rate up to, say, 73%.
This example should clarify why a Bayesian approach is productive here. If we use some historical data about conversion rates, we can adequately temper early results during the explore portion rather than exploit too eagerly. Each variant gets its own beta distribution based on the number of exposures, conversions, and an experiment-wide set of initial parameters, α and β. The initial α and β can be thought of as the number of conversions and non-converting exposures, respectively, to add to each variant distribution based on historical data. In the free throw example above, we may add 70 makes and 30 misses as the prior distribution, or if we’re much more confident in the baseline rate, 700 makes and 300 misses. The higher the initial parameters, the more new data will be required to change the posterior distribution.
When a request for a new assignment comes in, the Thompson Sampling algorithm samples from each variant beta distribution (the simple-random gem makes this easy in Ruby) and chooses the variant with the highest value. Unlike the Epsilon Greedy approach, this way we exploit much more aggressively once we’ve learned enough for the distributions to separate. At the same time, because there’s randomness / sampling involved, we never fully stop exploring either, which allows for the experiment to be much more responsive.
For these reasons, we proceeded with the Thompson Sampling algorithm.
Calculating Initial α and β
Similar to the Epsilon Greedy approach, the most difficult part of implementing the Thompson Sampling algorithm is choosing the initial parameter values. I created a simulation tool to do some research. I simulated hundreds of bandit experiments where there were 4 variants:
-
a true 10% conversion rate lift
-
a true 10% conversion rate drop
-
a neutral variant
-
a control
In a perfect world, within a few weeks' worth of simulated traffic, we should see the variant with the lift getting the most exposures. We also want to make sure that the variant with the drop gets the least amount of exposures. We can imagine two scenarios where the importance of each of these goals is much different:
-
a change in the font on the checkout page
-
choosing an image on a new SEM landing page
In scenario 1, we must be much more conservative, as it would be much worse for the losing variant to get more traffic than it would for the winning variant to get less traffic, because we could seriously affect the bottom line of the business. Meanwhile, in scenario 2, we want to learn quickly, and care much more about a potential winner rising to the top early. The admin UI gives you the option to choose whether to be conservative (avoid losing variants winning) or aggressive (maximize winning variants winning). In the free throw example above, the conservative approach would add many simulated makes and misses, while the aggressive approach would only add a few. Product managers can choose which strategy makes sense based on the location of the experiment and the amount of leverage the page has on the ezCater bottom line.
Takeaways
Multi-armed bandit experimentation is particularly useful for driving up conversion rates by testing subtle changes and converging on the most popular variant. They should not replace AB tests, especially on larger UX changes where analysis will be more complex. Our infrastructure made it possible to leverage the best tools for the job (Kafka, DynamoDB) while staying agile and finishing the product in a couple of months. Thompson Sampling proved to be the best option for the new assignment distribution, as it responds quickly to changes while constantly exploring the entire variant space.
